Betrachtet werden die Probleme der Modellierung, Simulation und des systematischen Entwurfs anwendungsspezifischer Instruktionssatzprozessoren (engl. application-specific instruction-set processors, ASIPs). Dazu gehören beispielsweise digitale Signalprozessoren (DSPs) und Mikrocontrollerarchitekturen. Untersucht werden neuartige Simulationskonzepte sowie bessere Compilerverfahren zur Unterstützung dieser Klasse von Architekturen.
BUILDABONG stands for Building special computer architectures based on architecture and compiler co-generation.
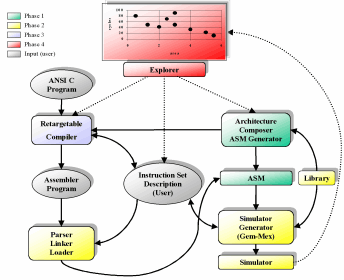
The goal is to investigate architecture trade-offs of special-purpose processor architectures, in particular specialized instruction set computers – ASIPs and dedicated processor architectures. Examples of these computers are embedded controllers or digital signal processors (DSPs). The project is divided into four different phases.
The goal is to investigate architecture trade-offs of special-purpose processor architectures, in particular specialized instruction set computers – ASIPs and dedicated processor architectures. Examples of these computers are embedded controllers or digital signal processors (DSPs). The project is divided into four different phases.
Phase 1: Architecture Description and Composition
An object-oriented tool for hierarchical graphical entry and composition of high-level architecture components of a processor architecture is conceptually developed and implemented. For this purpose, a library of common high-level components to compose an architecture (e.g., address generation units, timers, buses, ALUs, register files, etc.) has been defined being parameterizable in bit width, number of inputs, etc. The tool provides a simulation interface to the simulation engine that is based on the formal semantics of ASMs (abstract state machines), see phase II. Therefore, a translation of a graphical architecture composition into an ASM description for simulation must be done after architecture entry (code generation of the ASM description).
Phase 2: Architecture Simulation
Our goal is to provide efficient and, at the same time timing-accurate simulations of specialized processor architectures, e.g., pipelined designs, VLIW datapath computers, etc.
On architecture levels higher or equal to the RT-level (register transfer level), instruction set simulation in software of a medium size processor design is known to be feasible. The RT-level is also the highest level of detailedness where cycle-accurate simulation is still possible. Many of today’s languages for describing processor architectures are either purely structural, or behavioral, but often not cycle-accurate.
Based on the formal model of abstract state machines introduced by Gurevich and our first experiences gained in instruction set simulation for a real ARM (Advanced Risc Machines) processor based on the GEM/MEX environment for ASM prototyping [1], cycle-level timing accurate simulation has been shown to be feasible. Based on the graphical entry of an architecture (phase I), the corresponding ASM description will be generated automatically (C-Code) and may be simulated using Anlauff’s [2] ASM debugger.
Phase 3: Compiler Generation
Given a description of the processor datapath and controller (phase I and II), instruction-set extraction deals with the task of automatic extraction of processor instructions in terms of register-transfer patterns. For certain types of architectures, e.g., DSP-like processors, this has been shown to be doable automatically. Afterwards, a given application source code must be compiled into this instruction set.
Particularly for embedded processors, time spent in compilation might not be that critical in case better optimized code is the gain. In this area, only first approaches tried to tackle the important problem of phase coupling of the compiler phases code selection, register allocation, and scheduling. For specialized architectures with regular, parallel datapath units, we have and will investigate special compiler optimization methods to restructure the code prior to code generation (i.e. loop-based transformations on regular algorithms). A mixture of compiler techniques for regular dedicated and irregular datapath architectures might be a new approach for code generation in special-purpose compilers.
Phase 4: Optimal Architecture/Compiler Co-design
In the final phase, it should be possible to generate a set of possible architectures and their associated optimizing compiler in order to best perform a given class of applications due to given constraints. Therefore, we have to trade off multiple design goals, e.g., hardware cost, execution time, code size, etc. Often, these design goals are conflicting so that it is impossible to find a design point which is optimal in all design parameters. Here, we prune the huge possible design space for an architecture/compiler codesign to a relatively small set of so-called Pareto-optimal design points.
The design space is spanned by both
- the backend design space spanned by architecture parameters, e.g.,number and types of functional units, register set structure, etc., and
- the frontend design space spanned by possible code optimization strategies of the associated compiler.
The main problems tackled in this phase are:
- to formalize such a trade-off as a multi-objective optimization problem,
- to formally define the design space for such an architecture/compiler co-exploration,
- to define the constraints on the architecture as adequate objective functions, and
- to develop a sophisticated optimization strategy in order to prune the huge design space to a preferably small set of Pareto-optimal design points in reasonable time.
Future work is to maintain a library with Pareto-optimal design points due to a given class of applications. With such a library, we are able to optimally adapt the architecture and compiler settings for each program of a benchmark individually by dynamic hardware reconfiguration.
„… One approach, detailed here by University of Michigan researchers Shighe Wang and Kang Shin, uses finite state machine techniques to build embedded software by selecting-and then connecting as needed-components in an asset library, specifying their behaviors and mapping them to an execution platform.
And Jürgen Teich and Ralph Weper of the University of Paderborn, Germany, have created a joined architecture/compiler environment that can generate implementations of architecture-specific instruction-set processors automatically; the instruction-set simulators and corresponding compilers use abstract state machine methodology…“from Programmable-chip methods get fresh look by Bernard Cole,
EE Times (02/16/01)